Kafka
Port's Kafka integration allows you to model Kafka resources in your software catalog and ingest data into them.
Overview
- Map and organize your desired Kafka resources and their metadata in Port (see supported resources below).
- Watch for Kafka object changes (create/update/delete) in real-time, and automatically apply the changes to your entities in Port.
Setup
Choose one of the following installation methods:
- Real-time (self-hosted)
- Scheduled (CI)
Using this installation option means that the integration will be able to update Port in real time using webhooks.
Prerequisites
To install the integration, you need a Kubernetes cluster that the integration's container chart will be deployed to.
Please make sure that you have kubectl and helm installed on your machine, and that your kubectl CLI is connected to the Kubernetes cluster where you plan to install the integration.
If you are having trouble installing this integration, please refer to these troubleshooting steps.
For details about the available parameters for the installation, see the table below.
- Helm
- ArgoCD
To install the integration using Helm:
-
Go to the Kafka data source page in your portal.
-
Select the
Real-time and always onmethod:
-
A
helmcommand will be displayed, with default values already filled out (e.g. your Port client ID, client secret, etc).
Copy the command, replace the placeholders with your values, then run it in your terminal to install the integration.
BaseUrl & webhook configuration
integration.config.appHost is deprecated: Please use liveEvents.baseUrl for webhook URL settings instead.
In order for the Kafka integration to update the data in Port on real-time changes in Kafka, you need to specify the liveEvents.baseUrl parameter.
The liveEvents.baseUrl parameter should be set to the url of your Kafka integration instance. Your integration instance needs to have the option to setup webhooks via http requests/recieve http requests , so please configure your network accordingly.
To test webhooks or live event delivery to your local environment, expose your local pod or service to the internet using ngrok:
ngrok http http://localhost:8000
This will provide a public URL you can use for webhook configuration and external callbacks during development.
If liveEvents.baseUrl is not provided, the integration will continue to function correctly. In such a configuration, to retrieve the latest information from the target system, the scheduledResyncInterval parameter has to be set, or a manual resync will need to be triggered through Port's UI.
Scalable Mode for Large Integrations
If you are deploying the integration at scale and want to decouple the resync process from the live events process (recommended for large or high-throughput environments), you can enable scalable mode by adding the following flags to your Helm install command:
--set workload.kind="CronJob" \
--set workload.cron.resyncTimeoutMinutes=60 \
--set scheduledResyncInterval="'*/60 * * * *'" \
--set liveEvents.worker.enabled=true
The port_region, port.baseUrl, portBaseUrl, port_base_url and OCEAN__PORT__BASE_URL parameters are used to select which instance or Port API will be used.
Port exposes two API instances, one for the EU region of Port, and one for the US region of Port.
- If you use the EU region of Port (https://app.port.io), your API URL is
https://api.port.io. - If you use the US region of Port (https://app.us.port.io), your API URL is
https://api.us.port.io.
To install the integration using ArgoCD:
-
Create a
values.yamlfile inargocd/my-ocean-kafka-integrationin your git repository with the content:initializePortResources: true
scheduledResyncInterval: 120
integration:
identifier: my-ocean-kafka-integration
type: kafka
eventListener:
type: POLLING
secrets:
clusterConfMapping: KAFKA_CLUSTER_CONFIG_MAPPING
-
Install the
my-ocean-kafka-integrationArgoCD Application by creating the followingmy-ocean-kafka-integration.yamlmanifest:ArgoCD Application
Replace placeholders- Replace the placeholders for
YOUR_PORT_CLIENT_IDYOUR_PORT_CLIENT_SECRETandYOUR_GIT_REPO_URLwith your actual values.
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-ocean-kafka-integration
namespace: argocd
spec:
destination:
namespace: my-ocean-kafka-integration
server: https://kubernetes.default.svc
project: default
sources:
- repoURL: 'https://port-labs.github.io/helm-charts/'
chart: port-ocean
targetRevision: 0.9.5
helm:
valueFiles:
- $values/argocd/my-ocean-kafka-integration/values.yaml
parameters:
- name: port.clientId
value: YOUR_PORT_CLIENT_ID
- name: port.clientSecret
value: YOUR_PORT_CLIENT_SECRET
- name: port.baseUrl
value: https://api.getport.io
- repoURL: YOUR_GIT_REPO_URL
targetRevision: main
ref: values
syncPolicy:
automated:
prune: true
selfHeal: true
syncOptions:
- CreateNamespace=trueSelecting a Port API URL by account regionThe
port_region,port.baseUrl,portBaseUrl,port_base_urlandOCEAN__PORT__BASE_URLparameters are used to select which instance or Port API will be used.Port exposes two API instances, one for the EU region of Port, and one for the US region of Port.
- If you use the EU region of Port (https://app.port.io), your API URL is
https://api.port.io. - If you use the US region of Port (https://app.us.port.io), your API URL is
https://api.us.port.io.
- Replace the placeholders for
-
Apply your application manifest with
kubectl:kubectl apply -f my-ocean-kafka-integration.yaml
This table summarizes the available parameters for the installation.
| Parameter | Description | Example | Required |
|---|---|---|---|
port.clientId | Your port client id | ✅ | |
port.clientSecret | Your port client secret | ✅ | |
port.baseUrl | Your Port API URL - https://api.getport.io for EU, https://api.us.getport.io for US | ✅ | |
integration.secrets.clusterConfMapping | JSON object mapping Kafka cluster names to their client configurations. Each cluster config should include bootstrap.servers, security.protocol, and authentication details. See Cluster configuration examples for detailed examples. | ✅ | |
integration.eventListener.type | The event listener type. Read more about event listeners | ✅ | |
integration.type | The integration to be installed | ✅ | |
scheduledResyncInterval | The number of minutes between each resync. When not set the integration will resync for each event listener resync event. Read more about scheduledResyncInterval | ❌ | |
initializePortResources | Default true, When set to true the integration will create default blueprints and the port App config Mapping. Read more about initializePortResources | ❌ | |
sendRawDataExamples | Enable sending raw data examples from the third party API to port for testing and managing the integration mapping. Default is true | ❌ |
This workflow/pipeline will run the Kafka integration once and then exit, this is useful for scheduled ingestion of data.
If you want the integration to update Port in real time using webhooks you should use the Real-time (self-hosted) installation option.
- GitHub
- Jenkins
- Azure Devops
- GitLab
Make sure to configure the following Github Secrets:
| Parameter | Description | Example | Required |
|---|---|---|---|
OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING | JSON object mapping Kafka cluster names to their client configurations. Each cluster config should include bootstrap.servers, security.protocol, and authentication details. See Cluster configuration examples for detailed examples. | '{"my-cluster": {"bootstrap.servers": "broker1:9092", "security.protocol": "SASL_SSL", "sasl.mechanism": "SCRAM-SHA-256", "sasl.username": "user", "sasl.password": "pass"}}' | ✅ |
OCEAN__PORT__CLIENT_ID | Your Port client (How to get the credentials) id | ✅ | |
OCEAN__PORT__CLIENT_SECRET | Your Port client (How to get the credentials) secret | ✅ | |
OCEAN__PORT__BASE_URL | Your Port API URL - https://api.getport.io for EU, https://api.us.getport.io for US | ✅ | |
OCEAN__INITIALIZE_PORT_RESOURCES | Default true, When set to true the integration will create default blueprints and the port App config Mapping. Read more about initializePortResources | ❌ | |
OCEAN__SEND_RAW_DATA_EXAMPLES | Enable sending raw data examples from the third party API to port for testing and managing the integration mapping. Default is true | ❌ | |
OCEAN__INTEGRATION__IDENTIFIER | The identifier of the integration that will be installed | ❌ |
Here is an example for kafka-integration.yml workflow file:
name: Kafka Exporter Workflow
on:
workflow_dispatch:
schedule:
- cron: '0 */1 * * *' # Determines the scheduled interval for this workflow. This example runs every hour.
jobs:
run-integration:
runs-on: ubuntu-latest
timeout-minutes: 30 # Set a time limit for the job
steps:
- uses: port-labs/ocean-sail@v1
with:
type: 'kafka'
port_client_id: ${{ secrets.OCEAN__PORT__CLIENT_ID }}
port_client_secret: ${{ secrets.OCEAN__PORT__CLIENT_SECRET }}
port_base_url: https://api.getport.io
config: |
cluster_conf_mapping: ${{ secrets.OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING }}
Your Jenkins agent should be able to run docker commands.
Make sure to configure the following Jenkins Credentials of Secret Text type:
| Parameter | Description | Example | Required |
|---|---|---|---|
OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING | JSON object mapping Kafka cluster names to their client configurations. Each cluster config should include bootstrap.servers, security.protocol, and authentication details. See Cluster configuration examples for detailed examples. | '{"my-cluster": {"bootstrap.servers": "broker1:9092", "security.protocol": "SASL_SSL", "sasl.mechanism": "SCRAM-SHA-256", "sasl.username": "user", "sasl.password": "pass"}}' | ✅ |
OCEAN__PORT__CLIENT_ID | Your Port client (How to get the credentials) id | ✅ | |
OCEAN__PORT__CLIENT_SECRET | Your Port client (How to get the credentials) secret | ✅ | |
OCEAN__PORT__BASE_URL | Your Port API URL - https://api.getport.io for EU, https://api.us.getport.io for US | ✅ | |
OCEAN__INITIALIZE_PORT_RESOURCES | Default true, When set to true the integration will create default blueprints and the port App config Mapping. Read more about initializePortResources | ❌ | |
OCEAN__SEND_RAW_DATA_EXAMPLES | Enable sending raw data examples from the third party API to port for testing and managing the integration mapping. Default is true | ❌ | |
OCEAN__INTEGRATION__IDENTIFIER | The identifier of the integration that will be installed | ❌ |
Here is an example for Jenkinsfile groovy pipeline file:
pipeline {
agent any
stages {
stage('Run Kafka Integration') {
steps {
script {
withCredentials([
string(credentialsId: 'OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING', variable: 'OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING'),
string(credentialsId: 'OCEAN__PORT__CLIENT_ID', variable: 'OCEAN__PORT__CLIENT_ID'),
string(credentialsId: 'OCEAN__PORT__CLIENT_SECRET', variable: 'OCEAN__PORT__CLIENT_SECRET'),
]) {
sh('''
#Set Docker image and run the container
integration_type="kafka"
version="latest"
image_name="ghcr.io/port-labs/port-ocean-${integration_type}:${version}"
docker run -i --rm --platform=linux/amd64 \
-e OCEAN__EVENT_LISTENER='{"type":"ONCE"}' \
-e OCEAN__INITIALIZE_PORT_RESOURCES=true \
-e OCEAN__SEND_RAW_DATA_EXAMPLES=true \
-e OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING=$OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING \
-e OCEAN__PORT__CLIENT_ID=$OCEAN__PORT__CLIENT_ID \
-e OCEAN__PORT__CLIENT_SECRET=$OCEAN__PORT__CLIENT_SECRET \
-e OCEAN__PORT__BASE_URL='https://api.getport.io' \
$image_name
exit $?
''')
}
}
}
}
}
}
Your Azure Devops agent should be able to run docker commands. Learn more about agents here.
Variable groups store values and secrets you'll use in your pipelines across your project. Learn more
Setting Up Your Credentials
- Create a Variable Group: Name it port-ocean-credentials.
- Store the required variables (see the table below).
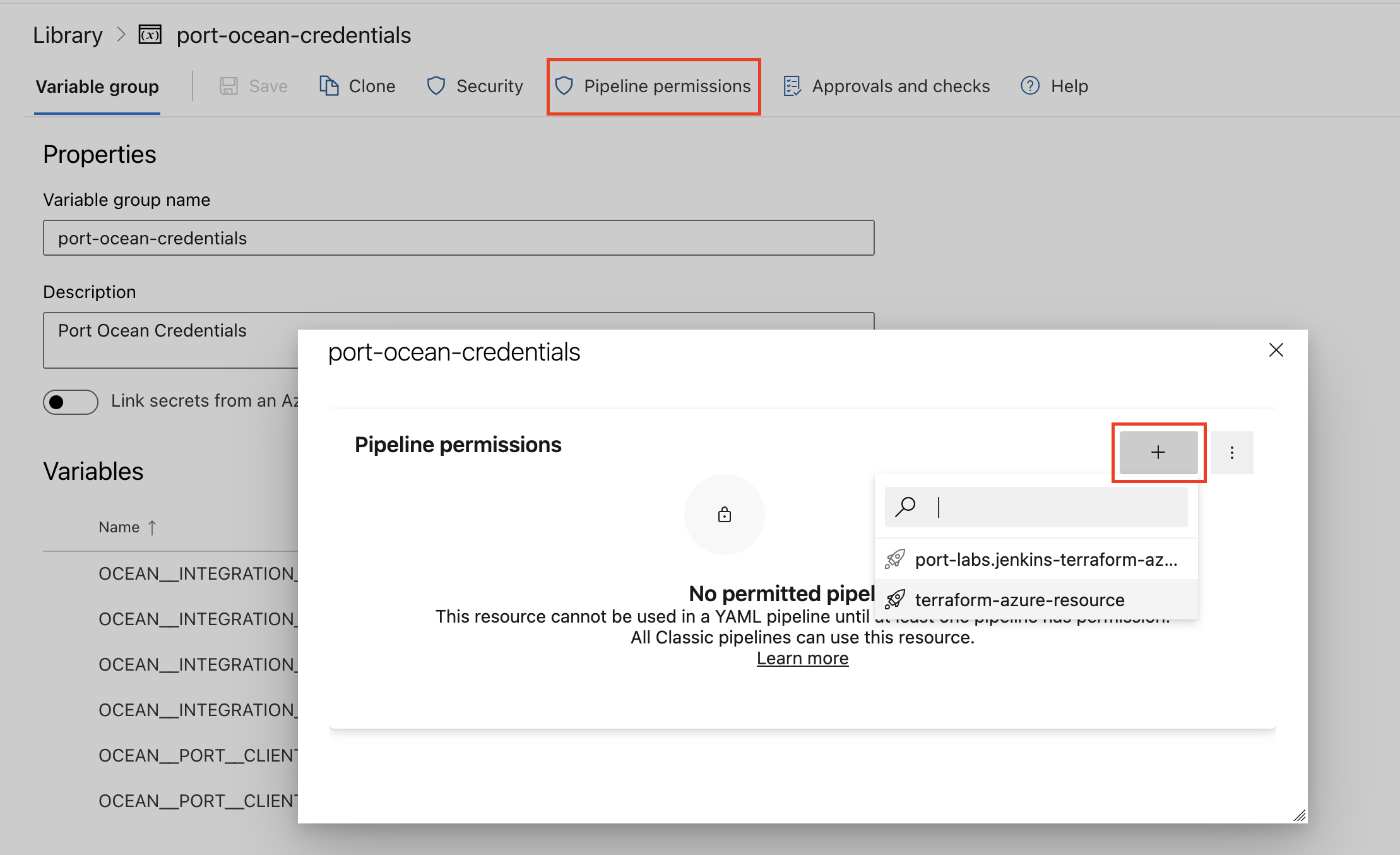
- Authorize Your Pipeline:
- Go to "Library" -> "Variable groups."
- Find port-ocean-credentials and click on it.
- Select "Pipeline Permissions" and add your pipeline to the authorized list.
| Parameter | Description | Example | Required |
|---|---|---|---|
OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING | JSON object mapping Kafka cluster names to their client configurations. Each cluster config should include bootstrap.servers, security.protocol, and authentication details. See Cluster configuration examples for detailed examples. | '{"my-cluster": {"bootstrap.servers": "broker1:9092", "security.protocol": "SASL_SSL", "sasl.mechanism": "SCRAM-SHA-256", "sasl.username": "user", "sasl.password": "pass"}}' | ✅ |
OCEAN__PORT__CLIENT_ID | Your Port client (How to get the credentials) id | ✅ | |
OCEAN__PORT__CLIENT_SECRET | Your Port client (How to get the credentials) secret | ✅ | |
OCEAN__PORT__BASE_URL | Your Port API URL - https://api.getport.io for EU, https://api.us.getport.io for US | ✅ | |
OCEAN__INITIALIZE_PORT_RESOURCES | Default true, When set to true the integration will create default blueprints and the port App config Mapping. Read more about initializePortResources | ❌ | |
OCEAN__SEND_RAW_DATA_EXAMPLES | Enable sending raw data examples from the third party API to port for testing and managing the integration mapping. Default is true | ❌ | |
OCEAN__INTEGRATION__IDENTIFIER | The identifier of the integration that will be installed | ❌ |
Here is an example for kafka-integration.yml pipeline file:
trigger:
- main
pool:
vmImage: "ubuntu-latest"
variables:
- group: port-ocean-credentials
steps:
- script: |
# Set Docker image and run the container
integration_type="kafka"
version="latest"
image_name="ghcr.io/port-labs/port-ocean-$integration_type:$version"
docker run -i --rm \
-e OCEAN__EVENT_LISTENER='{"type":"ONCE"}' \
-e OCEAN__INITIALIZE_PORT_RESOURCES=true \
-e OCEAN__SEND_RAW_DATA_EXAMPLES=true \
-e OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING=$(OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING) \
-e OCEAN__PORT__CLIENT_ID=$(OCEAN__PORT__CLIENT_ID) \
-e OCEAN__PORT__CLIENT_SECRET=$(OCEAN__PORT__CLIENT_SECRET) \
-e OCEAN__PORT__BASE_URL='https://api.getport.io' \
$image_name
exit $?
displayName: 'Ingest Data into Port'
Make sure to configure the following GitLab variables:
| Parameter | Description | Example | Required |
|---|---|---|---|
OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING | JSON object mapping Kafka cluster names to their client configurations. Each cluster config should include bootstrap.servers, security.protocol, and authentication details. See Cluster configuration examples for detailed examples. | '{"my-cluster": {"bootstrap.servers": "broker1:9092", "security.protocol": "SASL_SSL", "sasl.mechanism": "SCRAM-SHA-256", "sasl.username": "user", "sasl.password": "pass"}}' | ✅ |
OCEAN__PORT__CLIENT_ID | Your Port client (How to get the credentials) id | ✅ | |
OCEAN__PORT__CLIENT_SECRET | Your Port client (How to get the credentials) secret | ✅ | |
OCEAN__PORT__BASE_URL | Your Port API URL - https://api.getport.io for EU, https://api.us.getport.io for US | ✅ | |
OCEAN__INITIALIZE_PORT_RESOURCES | Default true, When set to true the integration will create default blueprints and the port App config Mapping. Read more about initializePortResources | ❌ | |
OCEAN__SEND_RAW_DATA_EXAMPLES | Enable sending raw data examples from the third party API to port for testing and managing the integration mapping. Default is true | ❌ | |
OCEAN__INTEGRATION__IDENTIFIER | The identifier of the integration that will be installed | ❌ |
Here is an example for .gitlab-ci.yml pipeline file:
default:
image: docker:24.0.5
services:
- docker:24.0.5-dind
before_script:
- docker info
variables:
INTEGRATION_TYPE: kafka
VERSION: latest
stages:
- ingest
ingest_data:
stage: ingest
variables:
IMAGE_NAME: ghcr.io/port-labs/port-ocean-$INTEGRATION_TYPE:$VERSION
script:
- |
docker run -i --rm --platform=linux/amd64 \
-e OCEAN__EVENT_LISTENER='{"type":"ONCE"}' \
-e OCEAN__INITIALIZE_PORT_RESOURCES=true \
-e OCEAN__SEND_RAW_DATA_EXAMPLES=true \
-e OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING=$OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING \
-e OCEAN__PORT__CLIENT_ID=$OCEAN__PORT__CLIENT_ID \
-e OCEAN__PORT__CLIENT_SECRET=$OCEAN__PORT__CLIENT_SECRET \
-e OCEAN__PORT__BASE_URL='https://api.getport.io' \
$IMAGE_NAME
rules: # Run only when changes are made to the main branch
- if: '$CI_COMMIT_BRANCH == "main"'
The port_region, port.baseUrl, portBaseUrl, port_base_url and OCEAN__PORT__BASE_URL parameters are used to select which instance or Port API will be used.
Port exposes two API instances, one for the EU region of Port, and one for the US region of Port.
- If you use the EU region of Port (https://app.port.io), your API URL is
https://api.port.io. - If you use the US region of Port (https://app.us.port.io), your API URL is
https://api.us.port.io.
For advanced configuration such as proxies or self-signed certificates, click here.
Cluster config mapping examples
The clusterConfMapping parameter is crucial for connecting to your Kafka clusters.
The cluster configuration mapping should be a JSON object with cluster names as keys and Kafka client configurations as values. Each client configuration follows the standard Kafka client properties format.
Below are some examples of how to configure the clusterConfMapping parameter for different Kafka cluster configurations.
Basic SASL_SSL authentication
For clusters with SASL authentication over SSL:
Basic SASL_SSL authentication (click to expand)
- Helm/ArgoCD
- CI/CD Environment Variable
integration:
secrets:
clusterConfMapping: |
{
"production-cluster": {
"bootstrap.servers": "broker1:9092,broker2:9092,broker3:9092",
"security.protocol": "SASL_SSL",
"sasl.mechanism": "SCRAM-SHA-256",
"sasl.username": "your-username",
"sasl.password": "your-password"
},
"staging-cluster": {
"bootstrap.servers": "staging-broker1:9092,staging-broker2:9092",
"security.protocol": "SASL_SSL",
"sasl.mechanism": "SCRAM-SHA-256",
"sasl.username": "staging-username",
"sasl.password": "staging-password"
}
}
export OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING='{
"production-cluster": {
"bootstrap.servers": "broker1:9092,broker2:9092,broker3:9092",
"security.protocol": "SASL_SSL",
"sasl.mechanism": "SCRAM-SHA-256",
"sasl.username": "your-username",
"sasl.password": "your-password"
},
"staging-cluster": {
"bootstrap.servers": "staging-broker1:9092,staging-broker2:9092",
"security.protocol": "SASL_SSL",
"sasl.mechanism": "SCRAM-SHA-256",
"sasl.username": "staging-username",
"sasl.password": "staging-password"
}
}'
Plain text authentication
For clusters without SSL encryption:
Plain text authentication (click to expand)
- Helm/ArgoCD
- CI/CD Environment Variable
integration:
secrets:
clusterConfMapping: |
{
"internal-cluster": {
"bootstrap.servers": "internal-broker1:9092,internal-broker2:9092",
"security.protocol": "SASL_PLAINTEXT",
"sasl.mechanism": "PLAIN",
"sasl.username": "internal-username",
"sasl.password": "internal-password"
}
}
export OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING='{
"internal-cluster": {
"bootstrap.servers": "internal-broker1:9092,internal-broker2:9092",
"security.protocol": "SASL_PLAINTEXT",
"sasl.mechanism": "PLAIN",
"sasl.username": "internal-username",
"sasl.password": "internal-password"
}
}'
mTLS authentication
For clusters with mutual TLS authentication:
mTLS authentication (click to expand)
- Helm/ArgoCD
- CI/CD Environment Variable
integration:
secrets:
clusterConfMapping: |
{
"secure-cluster": {
"bootstrap.servers": "secure-broker1:9092,secure-broker2:9092",
"security.protocol": "SSL",
"ssl.ca.location": "/path/to/ca-cert.pem",
"ssl.certificate.location": "/path/to/client-cert.pem",
"ssl.key.location": "/path/to/client-key.pem",
"ssl.key.password": "key-password"
}
}
export OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING='{
"secure-cluster": {
"bootstrap.servers": "secure-broker1:9092,secure-broker2:9092",
"security.protocol": "SSL",
"ssl.ca.location": "/path/to/ca-cert.pem",
"ssl.certificate.location": "/path/to/client-cert.pem",
"ssl.key.location": "/path/to/client-key.pem",
"ssl.key.password": "key-password"
}
}'
Confluent cloud configuration
For Confluent Cloud clusters:
Confluent cloud configuration (click to expand)
- Helm/ArgoCD
- CI/CD Environment Variable
integration:
secrets:
clusterConfMapping: |
{
"confluent-cloud-cluster": {
"bootstrap.servers": "pkc-abcd85.us-west-2.aws.confluent.cloud:9092",
"security.protocol": "SASL_SSL",
"sasl.mechanism": "PLAIN",
"sasl.username": "your-api-key",
"sasl.password": "your-api-secret"
}
}
export OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING='{
"confluent-cloud-cluster": {
"bootstrap.servers": "pkc-abcd85.us-west-2.aws.confluent.cloud:9092",
"security.protocol": "SASL_SSL",
"sasl.mechanism": "PLAIN",
"sasl.username": "your-api-key",
"sasl.password": "your-api-secret"
}
}'
Advanced configuration with custom properties
For clusters requiring additional custom properties:
Advanced configuration with custom properties (click to expand)
- Helm/ArgoCD
- CI/CD Environment Variable
integration:
secrets:
clusterConfMapping: |
{
"advanced-cluster": {
"bootstrap.servers": "broker1:9092,broker2:9092,broker3:9092",
"security.protocol": "SASL_SSL",
"sasl.mechanism": "SCRAM-SHA-512",
"sasl.username": "advanced-username",
"sasl.password": "advanced-password",
"ssl.ca.location": "/path/to/ca-cert.pem",
"ssl.endpoint.identification.algorithm": "https",
"request.timeout.ms": 30000,
"session.timeout.ms": 10000,
"enable.auto.commit": false
}
}
export OCEAN__INTEGRATION__CONFIG__CLUSTER_CONF_MAPPING='{
"advanced-cluster": {
"bootstrap.servers": "broker1:9092,broker2:9092,broker3:9092",
"security.protocol": "SASL_SSL",
"sasl.mechanism": "SCRAM-SHA-512",
"sasl.username": "advanced-username",
"sasl.password": "advanced-password",
"ssl.ca.location": "/path/to/ca-cert.pem",
"ssl.endpoint.identification.algorithm": "https",
"request.timeout.ms": 30000,
"session.timeout.ms": 10000,
"enable.auto.commit": false
}
}'
You can configure multiple clusters in the same mapping by adding additional cluster configurations as shown in the examples above. Each cluster will be processed independently by the integration.
- Store sensitive information like passwords and API keys securely using your platform's secret management system.
- For Kubernetes deployments, use Kubernetes secrets to store the
clusterConfMappingvalue. - For CI/CD pipelines, use environment variable encryption features provided by your CI/CD platform.
Configuration
Port integrations use a YAML mapping block to ingest data from the third-party api into Port.
The mapping makes use of the JQ JSON processor to select, modify, concatenate, transform and perform other operations on existing fields and values from the integration API.
Default mapping configuration
This is the default mapping configuration for this integration:
Default mapping configuration (Click to expand)
resources:
- kind: cluster
selector:
query: 'true'
port:
entity:
mappings:
identifier: .name
title: .name
blueprint: '"kafkaCluster"'
properties:
controllerId: .controller_id
- kind: broker
selector:
query: 'true'
port:
entity:
mappings:
identifier: .cluster_name + "_" + (.id | tostring)
title: .cluster_name + " " + (.id | tostring)
blueprint: '"kafkaBroker"'
properties:
address: .address
region: .config."broker.rack"
version: .config."inter.broker.protocol.version"
config: .config
relations:
cluster: .cluster_name
- kind: topic
selector:
query: 'true'
port:
entity:
mappings:
identifier: .cluster_name + "_" + .name
title: .cluster_name + " " + .name
blueprint: '"kafkaTopic"'
properties:
replicas: .partitions[0].replicas | length
partitions: .partitions | length
compaction: .config."cleanup.policy" | contains("compact")
retention: .config."cleanup.policy" | contains("delete")
deleteRetentionTime: .config."delete.retention.ms"
partitionsMetadata: .partitions
config: .config
relations:
cluster: .cluster_name
brokers: '[.cluster_name + "_" + (.partitions[].replicas[] | tostring)] | unique'
- kind: consumer_group
selector:
query: 'true'
port:
entity:
mappings:
identifier: .cluster_name + "_" + .group_id
title: .group_id
blueprint: '"kafkaConsumerGroup"'
properties:
state: .state
members: '[.members[].client_id]'
coordinator: .coordinator.id
partition_assignor: .partition_assignor
is_simple_consumer_group: .is_simple_consumer_group
authorized_operations: .authorized_operations
relations:
cluster: .cluster_name
Monitoring and sync status
To learn more about how to monitor and check the sync status of your integration, see the relevant documentation.
Examples
Examples of blueprints and the relevant integration configurations:
Cluster
Cluster blueprint
{
"identifier": "kafkaCluster",
"title": "Cluster",
"icon": "Kafka",
"schema": {
"properties": {
"controllerId": {
"title": "Controller ID",
"type": "string"
}
}
}
}
Integration configuration
createMissingRelatedEntities: false
deleteDependentEntities: true
resources:
- kind: cluster
selector:
query: "true"
port:
entity:
mappings:
identifier: .name
title: .name
blueprint: '"kafkaCluster"'
properties:
controllerId: .controller_id
Broker
Broker blueprint
{
"identifier": "kafkaBroker",
"title": "Broker",
"icon": "Kafka",
"schema": {
"properties": {
"address": {
"title": "Address",
"type": "string"
},
"region": {
"title": "Region",
"type": "string"
},
"version": {
"title": "Version",
"type": "string"
},
"config": {
"title": "Config",
"type": "object"
}
}
},
"relations": {
"cluster": {
"target": "kafkaCluster",
"required": true,
"many": false
}
}
}
Integration configuration
createMissingRelatedEntities: false
deleteDependentEntities: true
resources:
- kind: broker
selector:
query: "true"
port:
entity:
mappings:
identifier: .cluster_name + "_" + (.id | tostring)
title: .cluster_name + " " + (.id | tostring)
blueprint: '"kafkaBroker"'
properties:
address: .address
region: .config."broker.rack"
version: .config."inter.broker.protocol.version"
config: .config
relations:
cluster: .cluster_name
Topic
Topic blueprint
{
"identifier": "kafkaTopic",
"title": "Topic",
"icon": "Kafka",
"schema": {
"properties": {
"replicas": {
"title": "Replicas",
"type": "number"
},
"partitions": {
"title": "Partitions",
"type": "number"
},
"compaction": {
"title": "Compaction",
"type": "boolean"
},
"retention": {
"title": "Retention",
"type": "boolean"
},
"deleteRetentionTime": {
"title": "Delete Retention Time",
"type": "number"
},
"partitionsMetadata": {
"title": "Partitions Metadata",
"type": "array"
},
"config": {
"title": "Config",
"type": "object"
}
}
},
"relations": {
"cluster": {
"target": "kafkaCluster",
"required": true,
"many": false
},
"brokers": {
"target": "kafkaBroker",
"required": false,
"many": true
}
}
}
Integration configuration
createMissingRelatedEntities: false
deleteDependentEntities: true
resources:
- kind: topic
selector:
query: "true"
port:
entity:
mappings:
identifier: .cluster_name + "_" + .name
title: .cluster_name + " " + .name
blueprint: '"kafkaTopic"'
properties:
replicas: .partitions[0].replicas | length
partitions: .partitions | length
compaction: .config."cleanup.policy" | contains("compact")
retention: .config."cleanup.policy" | contains("delete")
deleteRetentionTime: .config."delete.retention.ms"
partitionsMetadata: .partitions
config: .config
relations:
cluster: .cluster_name
brokers: '[.cluster_name + "_" + (.partitions[].replicas[] | tostring)] | unique'
Consumer Group
Consumer Group blueprint
{
"identifier": "kafkaConsumerGroup",
"title": "Consumer Group",
"icon": "Kafka",
"schema": {
"properties": {
"state": {
"title": "State",
"type": "string",
"description": "The current state of the consumer group."
},
"members": {
"title": "Members",
"type": "array",
"description": "List of members in the consumer group.",
"items": {
"type": "string"
}
},
"coordinator": {
"title": "Coordinator",
"type": "number",
"description": "Broker ID of the coordinator for the consumer group."
},
"partition_assignor": {
"title": "Partition Assignor",
"type": "string",
"description": "Strategy used to assign partitions to consumers."
},
"is_simple_consumer_group": {
"title": "Is Simple Consumer Group",
"type": "boolean",
"description": "Indicates if the group is a simple consumer group."
},
"authorized_operations": {
"title": "Authorized Operations",
"type": "array",
"description": "List of operations authorized for the consumer group.",
"items": {
"type": "string"
}
}
}
},
"calculationProperties": {},
"relations": {
"cluster": {
"target": "kafkaCluster",
"required": true,
"many": false
}
}
}
Integration configuration
createMissingRelatedEntities: false
deleteDependentEntities: true
resources:
- kind: consumer_group
selector:
query: 'true'
port:
entity:
mappings:
identifier: .cluster_name + "_" + .group_id
title: .group_id
blueprint: '"kafkaConsumerGroup"'
properties:
state: .state
members: .members | map(.client_id)
coordinator: .coordinator.id
partition_assignor: .partition_assignor
is_simple_consumer_group: .is_simple_consumer_group
authorized_operations: .authorized_operations
relations:
cluster: .cluster_name